I had originally intended to write some code to simulate quantum computers and implement some quantum algorithms. I’ll probably eventually do that but today I just want to look at quantum mechanics in its own right as a kind of generalisation of probability. This is probably going to be the most incomprehensible post I’ve written in this blog. On the other hand, even though I eventually talk about the philosophy of quantum mechanics, there’s some Haskell code to play with at every stage, and the codeives the same results as appear in physics papers, so maybe that will help give a handle on what I’m saying.
First get some Haskell fluff out of the way:
> import Prelude hiding (repeat)
> import Data.Map (toList,fromListWith)
> import Complex
> infixl 7 .*
Now define certain types of vector spaces. The idea is the a W b a is a vector in a space whose basis elements are labelled by objects of type a and where the coefficients are of type p.
> data W b a = W { runW :: [(a,b)] } deriving (Eq,Show,Ord)
This is very similar to standard probability monads except that I’ve allowed the probabilities to be types other than Float. Now we need a couple of ways to operate on these vectors.
mapW allows the application of a function transforming the probabilities…
> mapW f (W l) = W $ map (\(a,b) -> (a,f b)) l
and fmap applies a function to the basis element labels.
> instance Functor (W b) where
> fmap f (W a) = W $ map (\(a,p) -> (f a,p)) a
We want our vectors to support addition, multiplication, and actually form a monad. The definition of >>= is similar to that for other probability monads. Note how vector addition just concatenates our lists of probabilities. The problem with this is that if we have a vector like 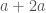 we’d like it to be reduced to
we’d like it to be reduced to 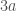 but in order to do that we need to be able to spot that the two terms
but in order to do that we need to be able to spot that the two terms  and
and 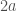 both contain multiples of the same vector, and to do that we need the fact that the labels are instances of
both contain multiples of the same vector, and to do that we need the fact that the labels are instances of Eq. Unfortunately we can’t do this conveniently in Haskell because of the lack of restricted datatypes and so to collect similar terms we need to use a separate collect function:
> instance Num b => Monad (W b) where
> return x = W [(x,1)]
> l >>= f = W $ concatMap (\(W d,p) -> map (\(x,q)->(x,p*q)) d) (runW $ fmap f l)
> a .* b = mapW (a*) b
> instance (Eq a,Show a,Num b) => Num (W b a) where
> W a + W b = W $ (a ++ b)
> a - b = a + (-1) .* b
> _ * _ = error "Num is annoying"
> abs _ = error "Num is annoying"
> signum _ = error "Num is annoying"
> fromInteger a = if a==0 then W [] else error "fromInteger can only take zero argument"
> collect :: (Ord a,Num b) => W b a -> W b a
> collect = W . toList . fromListWith (+) . runW
Now we can specialise to the two monads that interest us:
> type P a = W Float a
> type Q a = W (Complex Float) a
P is the (hopefully familiar if you’ve read Eric’s recent posts) probability monad. But Q allows complex probabilities. This is because quantum mechanics is a lot like probability theory with complex numbers and many of the rules of probability theory carry over.
Suppose we have a (non-quantum macroscopic) coin that we toss. It’s state might be described by:
> data Coin = Heads | Tails deriving (Eq,Show,Ord)
> coin1 = 0.5 .* return Heads + 0.5 .* return Tails :: P Coin
Suppose that if Albert sees a coin that is heads up he has a 50% chance of turning it over and if he sees a coin that is tails up he has a 25% chance of turning it over. We can describe Albert like this:
> albert Heads = 0.5 .* return Heads + 0.5 .* return Tails
> albert Tails = 0.25 .* return Heads + 0.75 .* return Tails
We can now ask what happens if Albert sees a coin originally turned up heads n times in a row:
> repeat 0 f = id
> repeat n f = repeat (n-1) f . f> (->-) :: a -> (a -> b) -> b
> g ->- f = f g
> (-><) :: Q a -> (a -> Q b) -> Q b
> g ->< f = g >>= f
> albert1 n = return Heads ->- repeat n (->< albert) ->- collect
Let me explain those new operators. ->- is just function application written from left to right. The > in the middle is intended to suggest the direction of data flow. ->< is just >>= but I’ve written it this way with the final < intended to suggest the way a function a -> M b ‘fans out’. Anyway, apropos of nothing else, notice how Albert approaches a steady state as n gets larger.
Quantum mechanics works similarly but with the following twist. When we come to observe the state of a quantum system it undergoes the following radical change:
> observe :: Ord a => Q a -> P a
> observe = W . map (\(a,w) -> (a,magnitude (w*w))) . runW . collect
Ie. the quantum state becomes an ordinary probabilistic one. This is called wavefunction collapse. Before collapse, the complex weights are called ‘amplitudes’ rather than probabilities. The business of physicists is largely about determining what these amplitudes are. For example, the well known Schrödinger equations is a lot like a kind of probabilistic diffusion, like a random walk, except with complex probabilities instead of amplitudes. (That’s why so many physicists have been hired into finance firms in recent years – stocks follow a random walk which has formal similarities to quantum physics.)
The rules of quantum mechanics are a bit like those of probability theory. In probability theory the sum of the probabilites must add to one. In addition, any process (like albert) must act in such a way that if the input sum of probabilities is one, then so is the output. This means that probabilistic process are stochastic. In quantum mechanics the sum of the squares of the magnitudes of the amplitudes must be one. Such a state is called ‘normalised’. All processes must be such that normalised inputs go to normalised outputs. Such processes are called unitary ones.
There’s a curious subtlety present in quantum mechanics. In classical probability theory you need to have the sum of the probabilities of your different events to sum to one. But it’s no good having events like “die turns up 1”, “die turns up 2”, “die turns up even” at the same time. “die turns up even” includes “die turns up 2”. So you always need to work with a mutually exclusive set of events. In quantum mechanics it can be pretty tricky to figure out what the mutually exclusive events are. For example, when considering the spin of an electron, there are no more mutually exclusive events beyond “spin up” and “spin down”. You might think “what about spin left?”. That’s just a mixture of spin up and spin down – and that fact is highly non-trivial and non-obvious. But I don’t want to discuss that now and it won’t affect the kinds of things I’m considering below.
So here’s an example of a quantum process a bit like albert above. For any angle  ,
, rotate turns a boolean state into a mixture of boolean states. For 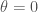 it just leaves the state unchanged and for
it just leaves the state unchanged and for  it inverts the state so it corresponds to the function
it inverts the state so it corresponds to the function Not. But for  it does something really neat: it is a kind of square root of
it does something really neat: it is a kind of square root of Not. Let’s see it in action:
> rotate :: Float -> Bool -> Q Bool
> rotate theta True = let theta' = theta :+ 0
> in cos (theta'/2) .* return True - sin (theta'/2) .* return False
> rotate theta False = let theta' = theta :+ 0
> in cos (theta'/2) .* return False + sin (theta'/2) .* return True
> snot = rotate (pi/2)
> repeatM n f = repeat n (>>= f)
> snot1 n = return True ->- repeatM n snot ->- observe
We can test it by running snot1 2 to see that two applications take you to where you started but that snot1 1 gives you a 50/50 chance of finding True or False. Nothing like this is possible with classical probability theory and it can only happen because complex numbers can ‘cancel each other out’. This is what is known as ‘destructive interference’. In classical probability theory you only get constructive interference because probabilities are always positive real numbers. (Note that repeatM is just a monadic version of repeat – we could have used it to simplify albert1 above so there’s nothing specifically quantum about it.)
Now for two more combinators:
> (=>=) :: P a -> (a -> b) -> P b
> g =>= f = fmap f g> (=><) :: P (Q a) -> (a -> Q b) -> P (Q b)
> g =>< f = fmap (>>= f) g
The first just uses fmap to apply the function. I’m using the = sign as a convention that the function is to be applied not at the top level but one level down within the datastructure. The second is simply a monadic version of the first. The reason we need the latter is that we’re going to have systems that have both kinds of uncertainty – classical probabilistic uncertainty as well as quantum uncertainty. We’ll also want to use the fact that P is a monad to convert doubly uncertain events to singly uncertain ones. That’s what join does:
> join :: P (P a) -> P a
> join = (>>= id)
OK, that’s enough ground work. Let’s investigate a physical process that can be studied in the lab: the Quantum Zeno effect, otherwise known as the fact that a watched pot never boils. First an example related to snot1:
> zeno1 n = return True ->- repeatM n (rotate (pi/fromInteger n)) ->- collect ->- observe
The idea is that we ‘rotate’ our system through an angle  but we do so in n stages. The fact that we do it in n stages makes no difference, we get the same result as doing it in one go. The slight complication is this: suppose we start with a probabilistic state of type
but we do so in n stages. The fact that we do it in n stages makes no difference, we get the same result as doing it in one go. The slight complication is this: suppose we start with a probabilistic state of type P a. If we let it evolve quantum mechanically it’ll turn into something of type P (Q a). On observation we get something of type P (P a). We need join to get a single probability distribution of type P a. The join is nothing mysterious, it just combines the outcome of two successive probabilistic processes into one using the usual laws of probability.
But here’s a variation on that theme. Now we carry out n stages, but after each one we observe the system causing wavefunction collapse:
> zeno2 n = return True ->- repeat n (
> \x -> x =>= return =>< rotate (pi/fromInteger n) =>= observe ->- join
> ) ->- collect
Notice what happens. In the former case we flipped the polarity of the input. In this case it remains closer to the original state. The higher we make n the closer it stays to its original state. (Not too high, start with small n. The code suffers from combinatorial explosion.) Here‘s a paper describing the actual experiment. Who needs all that messing about with sensitive equipment when you have a computer? 🙂
A state of the form P (Q a) is called a mixed state. Mixed states can get a bit hairy to deal with as you have this double level of uncertainty. It can get even trickier because you can sometimes observe just part of a quantum system rather than the whole system like oberve does. This inevitably leads mixed states. von Neumann came up with the notion of a density matrix to deal with this, although a P (Q a) works fine too. I also have a hunch there is an elegant way to handle them through an object of type P (Q (Q a)) that will eliminate the whole magnitude squared thing. However, I want to look at the quantum Zeno effect in another way that ultimately allows you deal with mixed states in another way. Unfortunately I don’t have time to explain this elimination today, but we can look at the general approach.
In this version I’m going to consider a quantum system that consists of the logical state in the Zeno examples, but also include the state of the observer. Now standard dogma says you can’t can’t form quantum states out of observers. In other words, you can’t form Q Observer where Observer is the state of the observer. It says you can only form P Observer. Whatever. I’m going to represent an experimenter using a list that representing the sequence of measurements they have made. Represent the complete system by a pair of type ([Bool],Bool). The first element of the pair is the experimenter’s memory and the second element is the state of the boolean variable being studied. When our experimenter makes a measurement of the boolean variable, its value is simply prepended to his or her memory:
> zeno3 n = return ([],True) ->- repeatM n (
> \(m,s) -> do
> s' <- rotate (pi/fromInteger n) s
> return (s:m,s')
> ) ->- observe =>= snd ->- collect
Note how we now delay the final observation until the end when we observe both the experimenter and the poor boolean being experimented on. We want to know the probabilities for the final boolean state so we apply snd so as to discard the state of the observer’s memory. Note how we get the same result as zeno2. (Note no mixed state, just an expanded quantum state that collapses to a classical probabilistic state.)
There’s an interesting philosophical implication in this. If we model the environment (in this case the experimenter is part of that environment) as part of a quantum system, we don’t need all the intermediate wavefunction collapses, just the final one at the end. So are the intermediate collapses real or not? The interaction with the environment is known as decoherence and some hope that wavefunction collapse can be explained away in terms of it.
Anyway, time for you to go and do something down-to-earth like gardening. Me, I’m washing the kitchen floor…
I must mention an important cheat I made above. When I model the experimenter’s memory as a list I’m copying the state of the measured experiment into a list. But you can’t simply copy data into a quantum register. One way to see this is that unitary processes are always invertible. Copy data into a register destroys the value that was there before and hence is not invertible. So instead, imagine that we really have an array that starts out zeroed out and that each time something is added to the list, the new result is xored into the next slot in the array. The list is just non-unitary looking, but convenient, shorthand for this unitary process.
PS I’m not convinced this LateX stuff is working. If something doesn’t make sense, looking around for equations that might have floated away 🙂 PPS wordpress teething troubles! I see that despite LaTeX support, wordpress is even more annoying than blogger in its handling of less than and greater than. It actually discards your HTML source sometimes. I’ve fixed one bit of discarded text. Additionally it also seems to discard backslash for no good reason. If you see something of the form a -> b it probably ought to be “backslash” a -> b. Apart from that, the code seems to work when copied and pasted from the blog into ghc.
